A Decision Support System for Irrigation Management: Analysis and Implementation of Different Learning Techniques

 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection Platform
- (1)
- soil matric potential measured by MPS-6 sensors (Decagon devices, Inc., Pullman, WA 99163, USA) (Figure 2a);
- (2)
- volumetric water content (VWC, soil moisture) measured by 10HS sensors (Decagon devices, Inc. Pullman, WA, USA) (Figure 2b);
- (3)
- volumetric water content, bulk electrical conductivity, and soil temperature measured by 5TE sensors (Decagon Devices, Inc. Pullman, WA, USA) (Figure 2c);
- (4)
- volume of water supplied during the previous week, measured with flowmeters (Apator POWOGAZ JS-04, Poland) (Figure 2d).
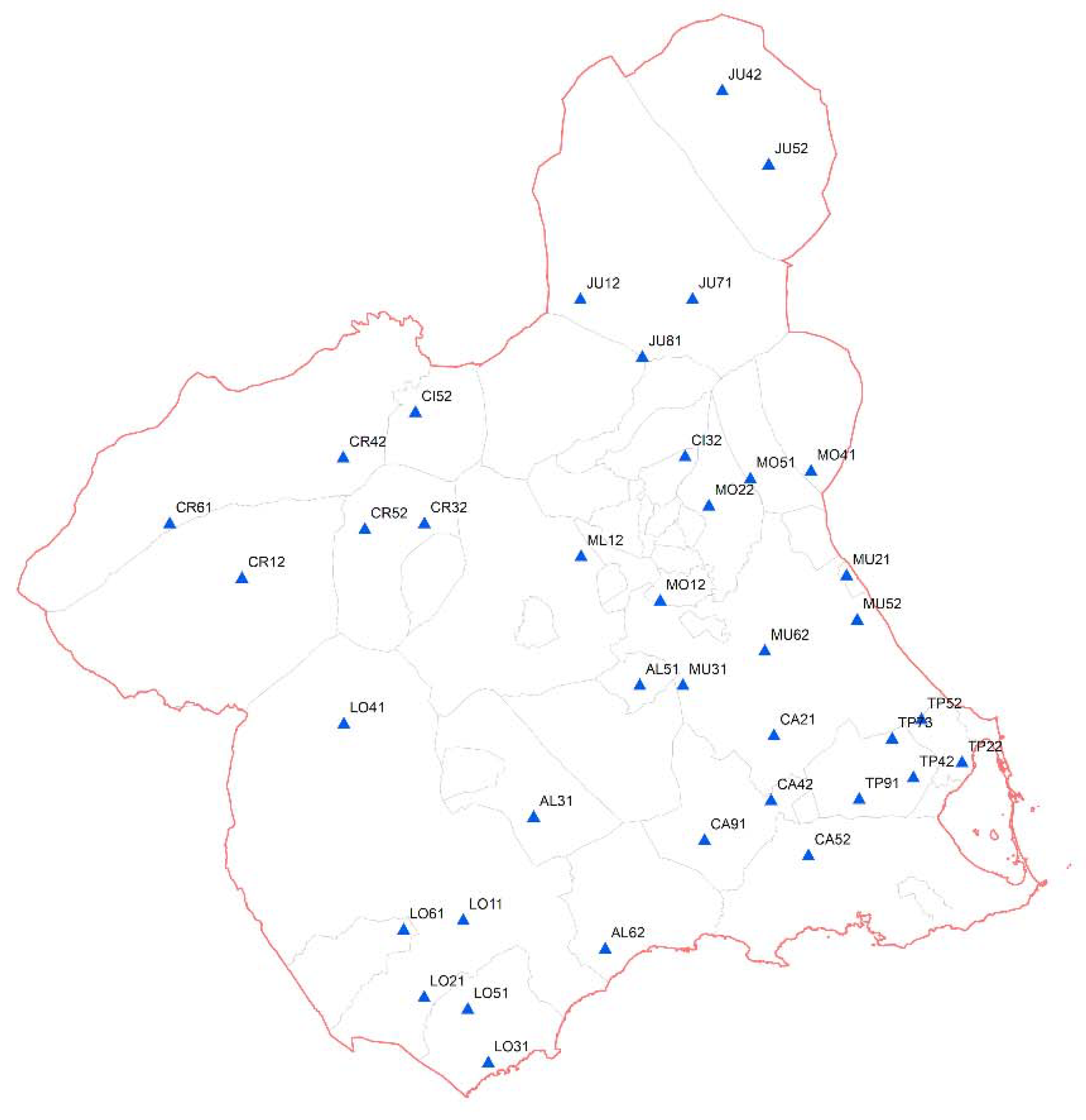
2.2. Plot and Report Description
2.3. Irrigation Decision Support System (IDSS)
2.3.1. Description of the Output and Input Variables
- Regarding the set of possible input variables, the selection was made according to the main information used by the agronomists when developing the irrigation reports, such as the total water needs (TWN), the soil water status, the amount of water applied previously, and the critical period of the crop: in the case of citrus trees, the main critical periods are flowering and fruit setting (Stage I), and a second period when fruit is growing fast (Stage II).
- However, there are more factors that might affect irrigation prediction (such as the weather prediction, the possible irrigation cutoff in the area, etc.), and those factors are not taken into account by the agronomist. This could be a limitation of this IDSS.
- The selection of a suitable set of features is crucial for good performances in the prediction models. In this sense, a selection procedure similar to that depicted in [36] was developed. The inputs that perform best in this new context were the following:
- daily average of the matric potential of the last 5 d (five inputs);
- the TWN (one input);
- the water applied (sensor measured) during the previous week (one input);
- a binary value indicating whether or not the crop is in a period where the fruit is gaining weight (one input).
- The daily average of the soil matric potential gives representative information about the conditions of the soil in the previous week. The TWN provides the theoretical irrigation volume for the crops in a specific area with specific weather conditions. The quantity of water for the last week is a hint of what the water requirement for the next week should be, as the water requirements of one week and the next are highly correlated. Finally, the period of the crop helps to finer tune the irrigation quantity: periods without fruit are less critical than those in which the fruit is present on the crop [27,45].
2.3.2. Linear Regression
2.3.3. Regression Trees: Bagging Regression and Random Forest Regression
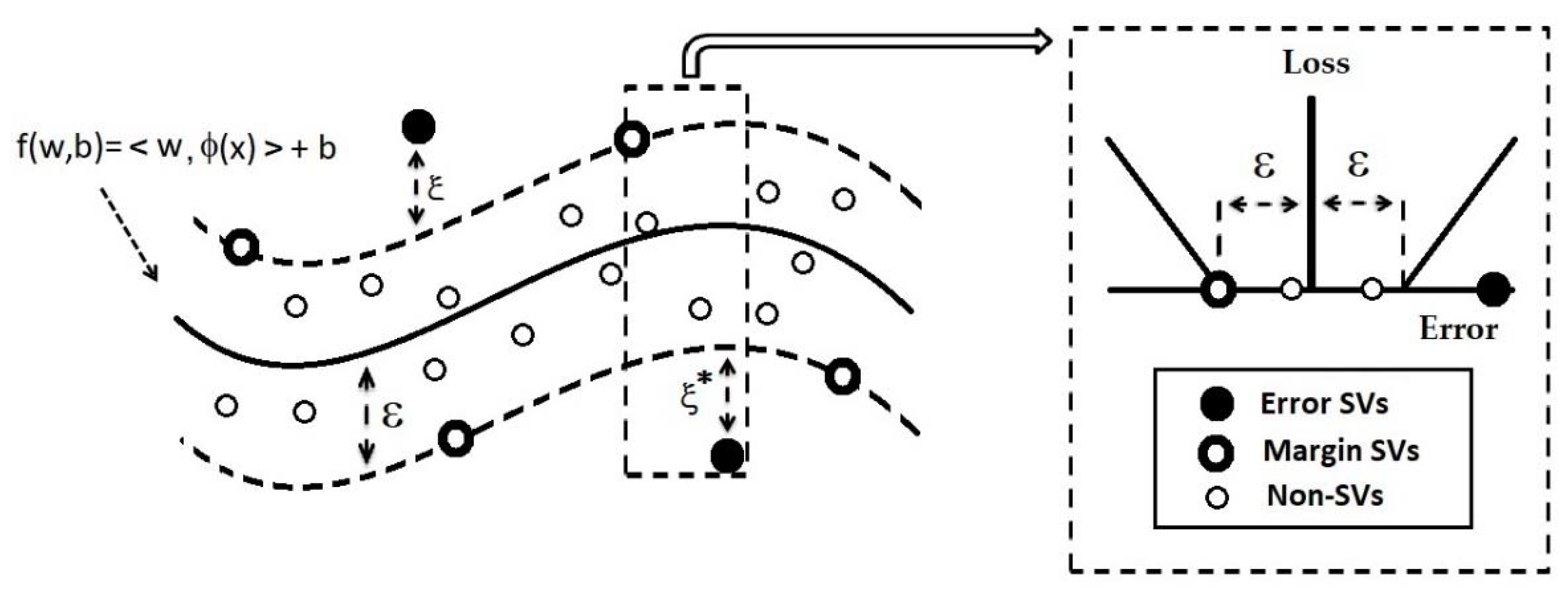
2.3.4. Support Vector Regression
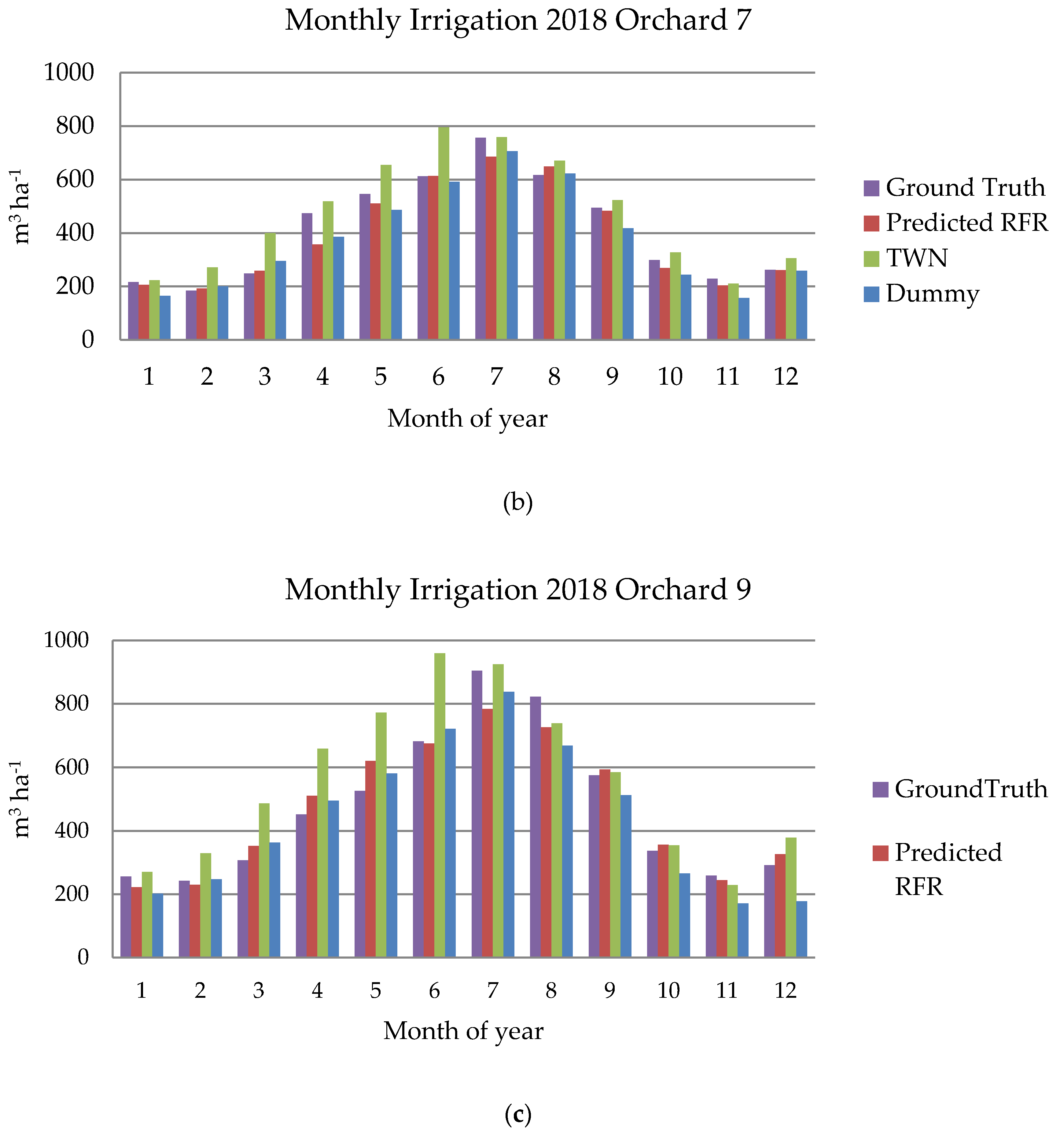
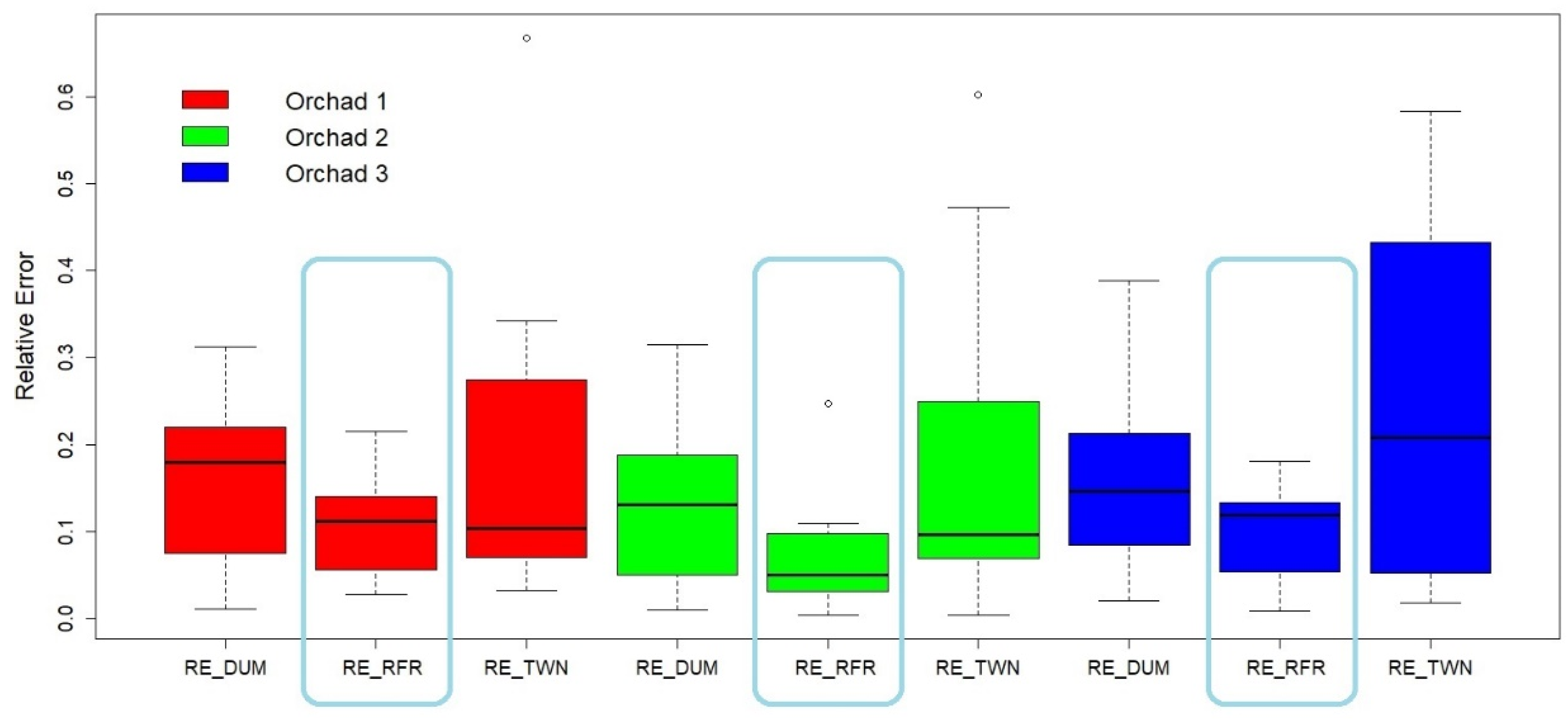
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Domingo, R.; Ruiz-Sánchez, M.C.; Sánchez-Blanco, M.J.; Torrecillas, A. Water relations, growth and yield of Fino lemon trees under regulated deficit irrigation. Irrig. Sci. 1996, 16, 115–123. [Google Scholar] [CrossRef]
- Torrecillas, A.; Alarcón, J.J.; Domingo, R.; Planes, J.; Sánchez-Blanco, M.J. Strategies for drought resistance in leaves of two almond cultivars. Plant Sci. 1996, 118, 135–143. [Google Scholar] [CrossRef]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Ullah Khan, S. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Navarro-Hellín, H.; Torres-Sánchez, R.; Soto-Valles, F.; Albaladejo-Pérez, C.; López-Riquelme, J.A.; Domingo-Miguel, R. A wireless sensors architecture for efficient irrigation water management. Agric. Water Manag. 2015, 151. [Google Scholar] [CrossRef] [Green Version]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Futur. Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Davis, S.L.; Dukes, M.D.; Miller, G.L. Landscape irrigation by evapotranspiration-based irrigation controllers under dry conditions in Southwest Florida. Agric. Water Manag. 2009, 96, 1828–1836. [Google Scholar] [CrossRef]
- Zhang, X.; Khachatryan, H. Investigating homeowners’ preferences for smart irrigation technology features. Water 2019, 11, 1996. [Google Scholar] [CrossRef] [Green Version]
- Davis, S.L.; Dukes, M.D. Irrigation scheduling performance by evapotranspiration-based controllers. Agric. Water Manag. 2010, 98, 19–28. [Google Scholar] [CrossRef]
- Gutierrez, J.; Villa-Medina, J.F.; Nieto-Garibay, A.; Porta-Gandara, M.A. Automated irrigation system using a wireless sensor network and GPRS module. IEEE Trans. Instrum. Meas. 2014, 63, 166–176. [Google Scholar] [CrossRef]
- Campbell, J.E. Dielectric properties and influence of conductivity in soils at one to fifty megahertz. Soil Sci. Soc. Am. J. 1990, 54, 332–341. [Google Scholar] [CrossRef]
- Visconti, F.; de Paz, J.M.; Martínez, D.; Molina, M.J. Laboratory and field assessment of the capacitance sensors Decagon 10HS and 5TE for estimating the water content of irrigated soils. Agric. Water Manag. 2014, 132, 111–119. [Google Scholar] [CrossRef]
- Kizito, F.; Campbell, C.S.; Campbell, G.S.; Cobos, D.R.; Teare, B.L.; Carter, B.; Hopmans, J.W. Frequency, electrical conductivity and temperature analysis of a low-cost capacitance soil moisture sensor. J. Hydrol. 2008, 352, 367–378. [Google Scholar] [CrossRef]
- Kargas, G.; Soulis, K.X. Performance evaluation of a recently developed soil water content, dielectric permittivity, and bulk electrical conductivity electromagnetic sensor. Agric. Water Manag. 2019, 213, 568–579. [Google Scholar] [CrossRef]
- González-Teruel, J.D.; Torres-Sánchez, R.; Blaya-Ros, P.J.; Toledo-Moreo, A.B.; Jiménez-Buendía, M.; Soto-Valles, F. Design and calibration of a low-cost SDI-12 soil moisture sensor. Sensors 2019, 19, 491. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barker, J.B.; Franz, T.E.; Heeren, D.M.; Neale, C.M.U.; Luck, J.D. Soil water content monitoring for irrigation management: A geostatistical analysis. Agric. Water Manag. 2017, 188, 36–49. [Google Scholar] [CrossRef] [Green Version]
- Gavilán, V.; Lillo-Saavedra, M.; Holzapfel, E.; Rivera, D.; García-Pedrero, A. Seasonal crop water balance using harmonized Landsat-8 and Sentinel-2 time series data. Water 2019, 11, 2236. [Google Scholar] [CrossRef] [Green Version]
- Jones, H.G. Use of infrared thermometry for estimation of stomatal conductance as a possible aid to irrigation scheduling. Agric. For. Meteorol. 1999, 95, 139–149. [Google Scholar] [CrossRef]
- García-Tejero, I.F.; Ortega-Arévalo, C.J.; Iglesias-Contreras, M.; Moreno, J.M.; Souza, L.; Tavira, S.C.; Durán-Zuazo, V.H. Assessing the crop-water status in almond (Prunus dulcis mill.) trees via thermal imaging camera connected to smartphone. Sensors 2018, 18, 1050. [Google Scholar] [CrossRef] [Green Version]
- Jackson, R.D.; Idso, S.B.; Reginato, R.J.; Pinter, P.J. Canopy temperature as a crop water stress indicator. Water Resour. Res. 1981, 17, 1133–1138. [Google Scholar] [CrossRef]
- Luthra, S.K.; Kaledhonkar, M.J.; Singh, O.P.; Tyagi, N.K. Design and development of an auto irrigation system. Agric. Water Manag. 1997, 33, 169–181. [Google Scholar] [CrossRef]
- Panigrahi, P.; Raychaudhuri, S.; Thakur, A.K.; Nayak, A.K.; Sahu, P.; Ambast, S.K. Automatic drip irrigation scheduling effects on yield and water productivity of banana. Sci. Hortic. (Amsterdam). 2019, 257. [Google Scholar] [CrossRef]
- Osroosh, Y.; Troy Peters, R.; Campbell, C.S.; Zhang, Q. Automatic irrigation scheduling of apple trees using theoretical crop water stress index with an innovative dynamic threshold. Comput. Electron. Agric. 2015, 118, 193–203. [Google Scholar] [CrossRef]
- Field Comparison of Tensiometer and Granular Matrix Sensor Automatic Drip Irrigation on Tomato in: HortTechnology Volume 15 Issue 3 (2005). Available online: https://journals.ashs.org/horttech/view/journals/horttech/15/3/article-p584.xml (accessed on 3 December 2019).
- Cáceres, R.; Casadesús, J.; Marfà, O. Adaptation of an automatic irrigation-control tray system for outdoor nurseries. Biosyst. Eng. 2007, 96, 419–425. [Google Scholar] [CrossRef]
- Bacci, L.; Battista, P.; Rapi, B. An integrated method for irrigation scheduling of potted plants. Sci. Hortic. (Amsterdam) 2008, 116, 89–97. [Google Scholar] [CrossRef]
- Casadesús, J.; Mata, M.; Marsal, J.; Girona, J. A general algorithm for automated scheduling of drip irrigation in tree crops. Comput. Electron. Agric. 2012, 83, 11–20. [Google Scholar] [CrossRef]
- Puerto, P.; Domingo, R.; Torres, R.; Pérez-Pastor, A.; García-Riquelme, M. Remote management of deficit irrigation in almond trees based on maximum daily trunk shrinkage: Water relations and yield. Agric. Water Manag. 2013, 126, 33–45. [Google Scholar] [CrossRef]
- Li, M.; Sui, R.; Meng, Y.; Yan, H. A real-time fuzzy decision support system for alfalfa irrigation. Comput. Electron. Agric. 2019, 163. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Shen, Y.; Zhang, X.; Lei, Y. Web-based irrigation decision support system with limited inputs for farmers. Agric. Water Manag. 2018, 210, 279–285. [Google Scholar] [CrossRef]
- Giusti, E.; Marsili-Libelli, S. A fuzzy decision support system for irrigation and water conservation in agriculture. Environ. Model. Softw. 2015, 63, 73–86. [Google Scholar] [CrossRef]
- Pluchinotta, I.; Pagano, A.; Giordano, R.; Tsoukiàs, A. A system dynamics model for supporting decision-makers in irrigation water management. J. Environ. Manage. 2018, 223, 815–824. [Google Scholar] [CrossRef]
- Rupnik, R.; Kukar, M.; Vračar, P.; Košir, D.; Pevec, D.; Bosnić, Z. AgroDSS: A decision support system for agriculture and farming. Comput. Electron. Agric. 2018. [Google Scholar] [CrossRef]
- Goap, A.; Sharma, D.; Shukla, A.K.; Rama Krishna, C. An IoT based smart irrigation management system using Machine learning and open source technologies. Comput. Electron. Agric. 2018, 155, 41–49. [Google Scholar] [CrossRef]
- Goldstein, A.; Fink, L.; Meitin, A.; Bohadana, S.; Lutenberg, O.; Ravid, G. Applying machine learning on sensor data for irrigation recommendations: Revealing the agronomist’s tacit knowledge. Precis. Agric. 2018, 19, 421–444. [Google Scholar] [CrossRef]
- Rose, D.C.; Sutherland, W.J.; Parker, C.; Lobley, M.; Winter, M.; Morris, C.; Twining, S.; Ffoulkes, C.; Amano, T.; Dicks, L.V. Decision support tools for agriculture: Towards effective design and delivery. Agric. Syst. 2016, 149, 165–174. [Google Scholar] [CrossRef] [Green Version]
- Navarro-Hellín, H.; Martínez-del-Rincon, J.; Domingo-Miguel, R.; Soto-Valles, F.; Torres-Sánchez, R. A decision support system for managing irrigation in agriculture. Comput. Electron. Agric. 2016, 124. [Google Scholar] [CrossRef] [Green Version]
- Nawandar, N.K.; Satpute, V.R. IoT based low cost and intelligent module for smart irrigation system. Comput. Electron. Agric. 2019, 162, 979–990. [Google Scholar] [CrossRef]
- Romero, M.; Luo, Y.; Su, B.; Fuentes, S. Vineyard water status estimation using multispectral imagery from an UAV platform and machine learning algorithms for irrigation scheduling management. Comput. Electron. Agric. 2018, 147, 109–117. [Google Scholar] [CrossRef]
- Yamaç, S.S.; Todorovic, M. Estimation of daily potato crop evapotranspiration using three different machine learning algorithms and four scenarios of available meteorological data. Agric. Water Manag. 2020, 228. [Google Scholar] [CrossRef]
- Kisi, O. Modeling reference evapotranspiration using three different heuristic regression approaches. Agric. Water Manag. 2016, 169, 162–172. [Google Scholar] [CrossRef]
- Tang, D.; Feng, Y.; Gong, D.; Hao, W.; Cui, N. Evaluation of artificial intelligence models for actual crop evapotranspiration modeling in mulched and non-mulched maize croplands. Comput. Electron. Agric. 2018, 152, 375–384. [Google Scholar] [CrossRef]
- Feng, Y.; Cui, N.; Gong, D.; Zhang, Q.; Zhao, L. Evaluation of random forests and generalized regression neural networks for daily reference evapotranspiration modelling. Agric. Water Manag. 2017, 193, 163–173. [Google Scholar] [CrossRef]
- SIAM—Sistema de Información Agraria de Murcia. Available online: http://siam.imida.es/apex/f?p=101:1:699166260304082 (accessed on 3 April 2019).
- San-Segundo, R.; Navarro-Hellín, H.; Torres-Sánchez, R.; Hodgins, J.; de la Torre, F. Increasing robustness in the detection of freezing of gait in Parkinson’s disease. Electronics 2019, 8, 119. [Google Scholar] [CrossRef] [Green Version]
- Blanco, V.; Domingo, R.; Pérez-Pastor, A.; Blaya-Ros, P.J.; Torres-Sánchez, R. Soil and plant water indicators for deficit irrigation management of field-grown sweet cherry trees. Agric. Water Manag. 2018, 208. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin, Germany, 2013; ISBN 978-1-4614-7137-0. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Networks 1999. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghosh, S. SVM-PGSL coupled approach for statistical downscaling to predict rainfall from GCM output. J. Geophys. Res. Atmos. 2010. [Google Scholar] [CrossRef] [Green Version]
- Mattera, D.; Haykin, S. Support vector machines for dynamic reconstruction of a chaotic system. In Advances in Kernel Methods: Support Vector Learning; The MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Cherkassky, V.; Ma, Y. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw. 2004. [Google Scholar] [CrossRef] [Green Version]
- Bos, M.G.; Burton, M.A.; Molden, D.J. Irrigation and Drainage Performance Assessment: Practical Guidelines; CABI Publishing: Oxfordshire, UK, 2005; ISBN 0851999670. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Orchard | Crop Type | Variety | Age | Field Size | Sensors | Water EC | Report Number |
|---|---|---|---|---|---|---|---|
| 1 | Lemon | Fino 49 | 11 years | 5.5 ha | 1xMPS6 2x10HS | 1.2 dSm−1 | 32 |
| 2 | Lemon | Fino 95 | 10 years | 6.0 ha | 1xMPS6 2x10HS | 2.2 dSm−1 | 31 |
| 3 | Orange | Lanelate | 8 years | 6.0 ha | 2xMPS6 1x10HS | 1.6 dSm−1 | 44 |
| 4 | Lemon | Fino 95 | 12 years | 6.0 ha | 2xMPS6 1x10HS | 2.5 dSm−1 | 60 |
| 5 | Mandarin | Clemenville | 12 years | 6.0 ha | 2xMPS6 1x10HS | 1.0 dSm−1 | 44 |
| 6 | Mandarin | Orri (Malla) | 8 years | 5.5 ha | 2xMPS6 1x10HS | 2.0 dSm−1 | 70 |
| 7 | Mandarin | Orri | 7 years | 5.5 ha | 2xMPS6 1x10HS | 2.0 dSm−1 | 69 |
| 8 | Orange | Lane | 8 years | 6.0 ha | 2xMPS6 1x10HS | 2.0 dSm−1 | 60 |
| 9 | Lemon | Verna | 3 years | 6.0 ha | 2xMPS6 1x10HS | 1.6 dSm−1 | 74 |
| SVR | LR | RFR | Dummy | |
|---|---|---|---|---|
| Train | 16.7 m3 | 18.5 m3 | 6.65 m3 | 23.39 m3 |
| Test | 17.13 m3 | 19.5 m3 | 16.83 m3 | 24.85 m3 |
| SVR | LR | RFR | Dummy | |||||
|---|---|---|---|---|---|---|---|---|
| Orchard | Train | Test | Train | Test | Train | Test | Train | Test |
| 1 | 15.79 | 31.99 | 19.13 | 19.64 | 6.48 | 18.02 | 22.58 | 20.60 |
| 2 | 15.85 | 24.75 | 19.22 | 16.08 | 6.66 | 18.68 | 22.46 | 24. 4 |
| 3 | 15.11 | 30.48 | 17.59 | 30.87 | 6.29 | 25.53 | 21.30 | 34.25 |
| 4 | 15.16 | 23.72 | 18.67 | 26.12 | 6.10 | 24.04 | 22.58 | 20.97 |
| 5 | 15.04 | 22.17 | 18.78 | 21.90 | 6.41 | 21.32 | 21.79 | 26.44 |
| 6 | 15.88 | 15.23 | 19.41 | 16.50 | 6.75 | 13.76 | 23.08 | 18.00 |
| 7 | 15.33 | 19.70 | 18.88 | 20.01 | 6.48 | 20.06 | 22.62 | 21.74 |
| 8 | 16.26 | 11.93 | 19.92 | 10.88 | 6.74 | 14.98 | 23.40 | 16.08 |
| 9 | 15.59 | 17.43 | 19.03 | 18.95 | 6.51 | 17.84 | 21.71 | 25.46 |
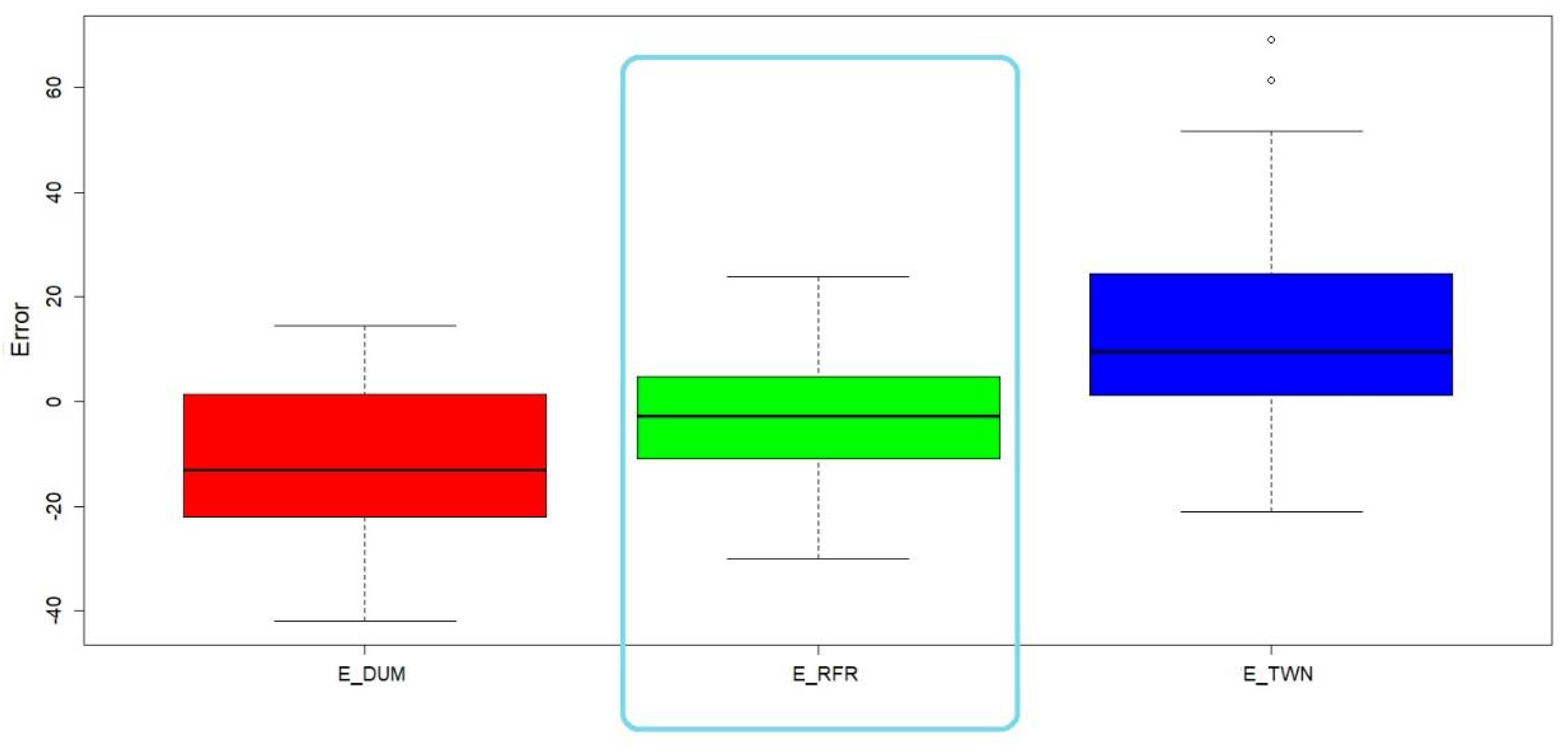
| Mean | 15.55 | 19.99 | 17.95 | 18.35 | 6.49 | 18.01 | 22.39 | 21.71 |
| Orchard | 1 | 2 | 3 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Dummy | RFR | TWN | Dummy | RFR | TWN | Dummy | RFR | TWN |
| RMSE | 76.32 | 58.92 | 140.31 | 52.64 | 43.76 | 83.86 | 76.32 | 58.92 | 140.31 |
| MRE | 0.16 | 0.10 | 0.18 | 0.13 | 0.07 | 0.18 | 0.17 | 0.10 | 0.24 |
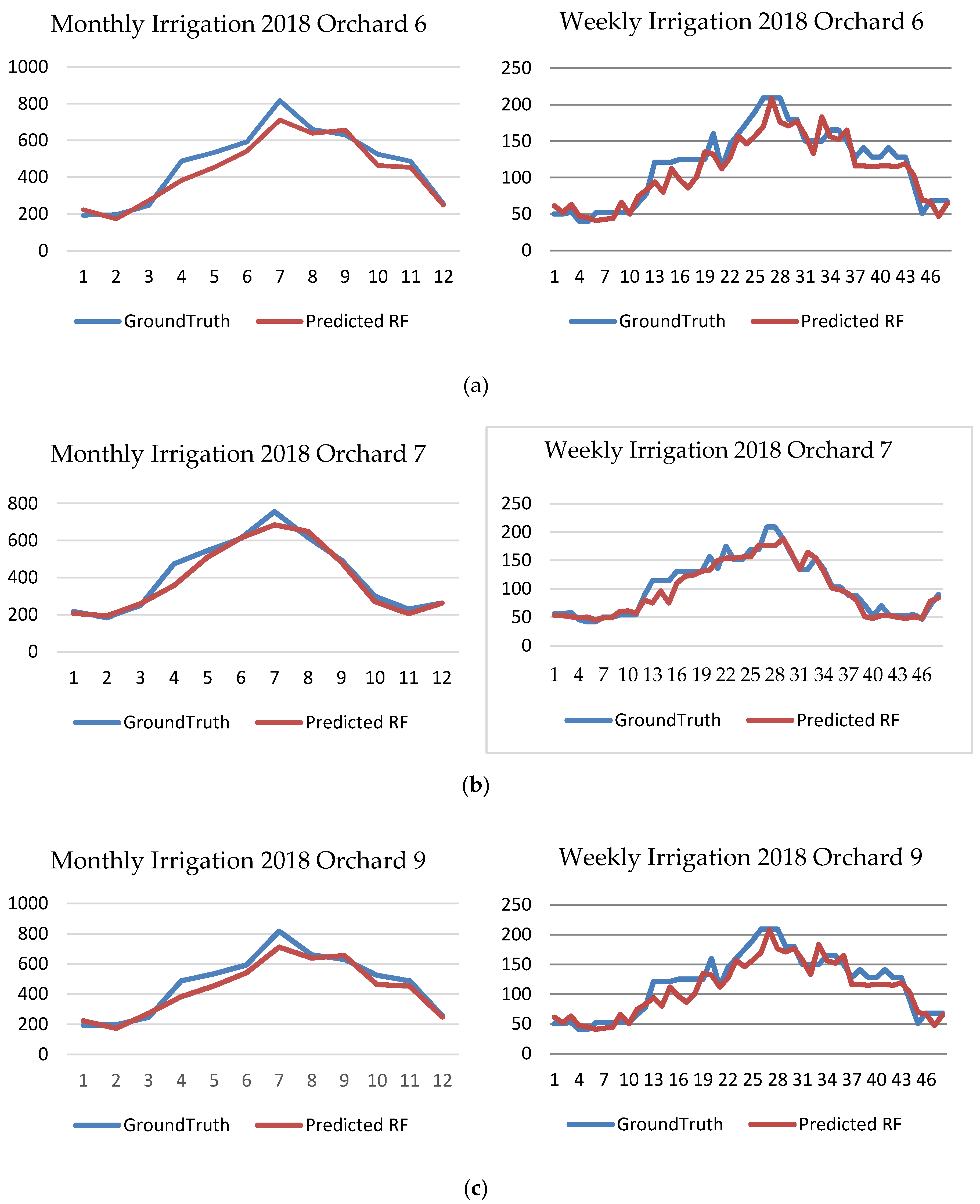
| Total water | 4860 m3 | 5218 m3 | 5912 m3 | 4534 m3 | 4690 m3 | 5660 m3 | 5242 m3 | 5642 m3 | 6684 m3 |
| Total water ground truth | 5626 m3 ha−1 | 4938 m3 ha−1 | 5635 m3 ha−1 | ||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torres-Sanchez, R.; Navarro-Hellin, H.; Guillamon-Frutos, A.; San-Segundo, R.; Ruiz-Abellón, M.C.; Domingo-Miguel, R. A Decision Support System for Irrigation Management: Analysis and Implementation of Different Learning Techniques. Water 2020, 12, 548. https://doi.org/10.3390/w12020548
Torres-Sanchez R, Navarro-Hellin H, Guillamon-Frutos A, San-Segundo R, Ruiz-Abellón MC, Domingo-Miguel R. A Decision Support System for Irrigation Management: Analysis and Implementation of Different Learning Techniques. Water. 2020; 12(2):548. https://doi.org/10.3390/w12020548
Chicago/Turabian StyleTorres-Sanchez, Roque, Honorio Navarro-Hellin, Antonio Guillamon-Frutos, Rubén San-Segundo, Maria Carmen Ruiz-Abellón, and Rafael Domingo-Miguel. 2020. "A Decision Support System for Irrigation Management: Analysis and Implementation of Different Learning Techniques" Water 12, no. 2: 548. https://doi.org/10.3390/w12020548