Using Random Forest Classification and Nationally Available Geospatial Data to Screen for Wetlands over Large Geographic Regions


Abstract
:1. Introduction
2. Materials and Methods
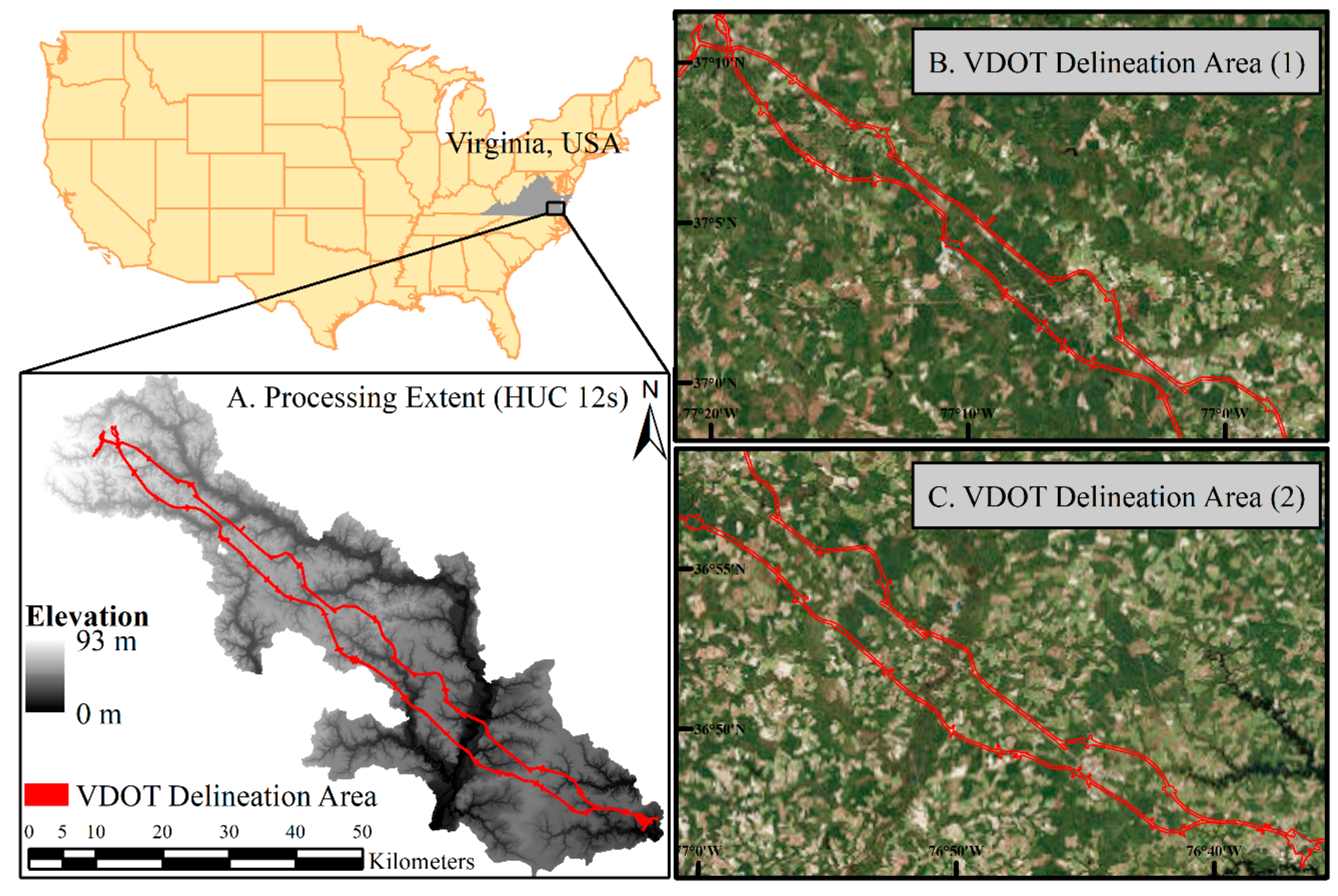
2.1. Study Area
2.2. Input Data and Preprocessing
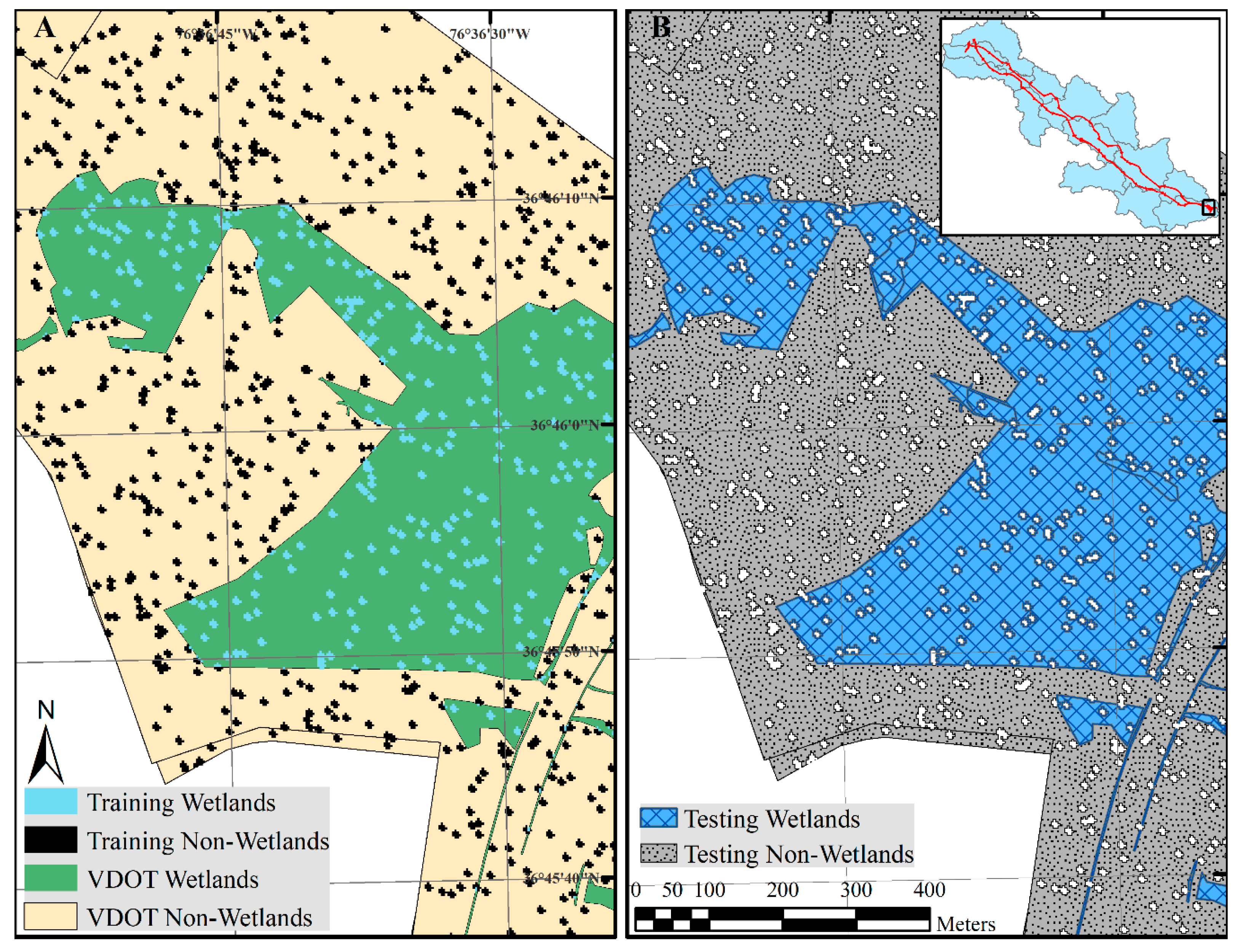
2.2.1. Wetland Delineations (Training and Testing Data)
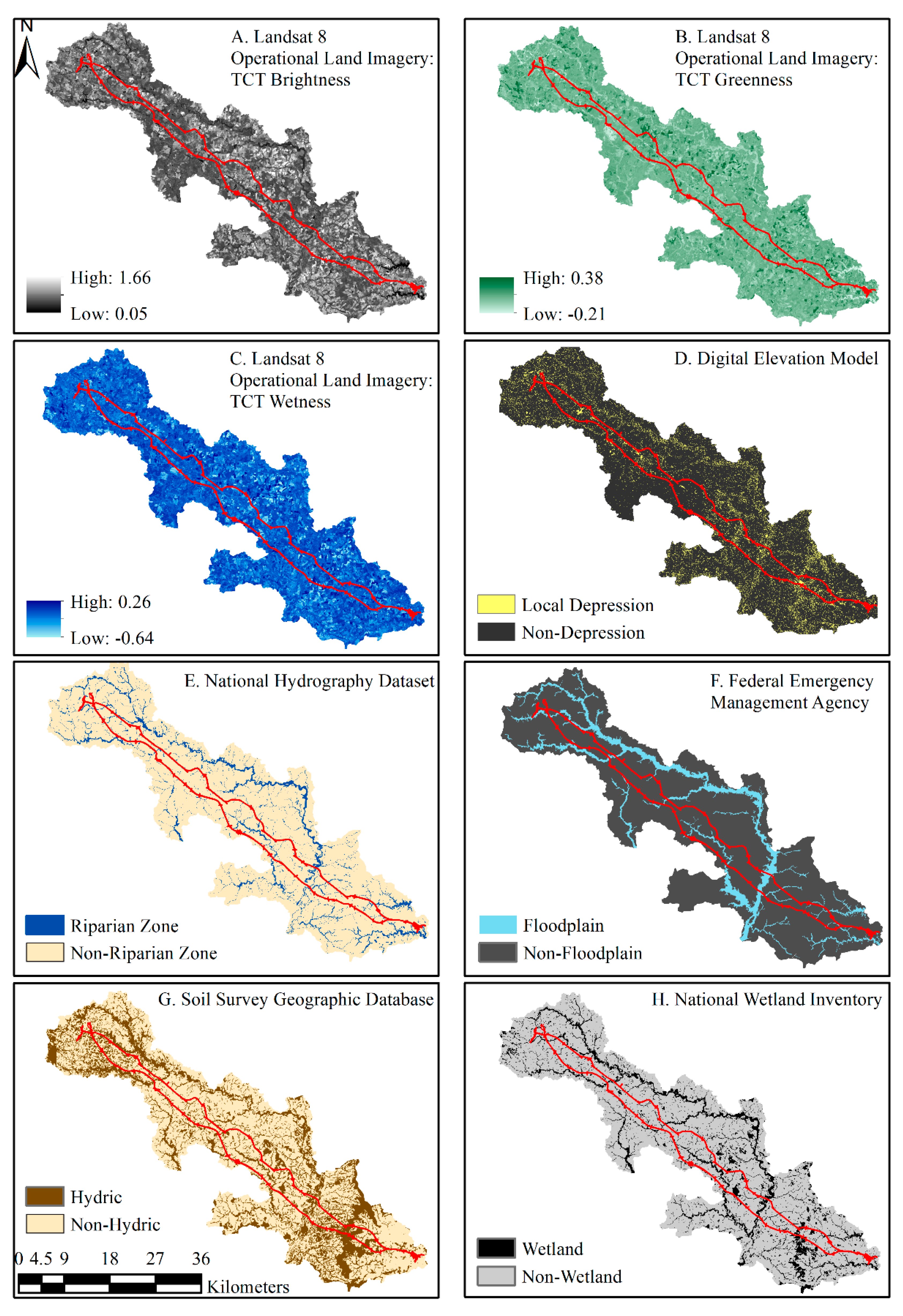
2.2.2. National-Scale Data
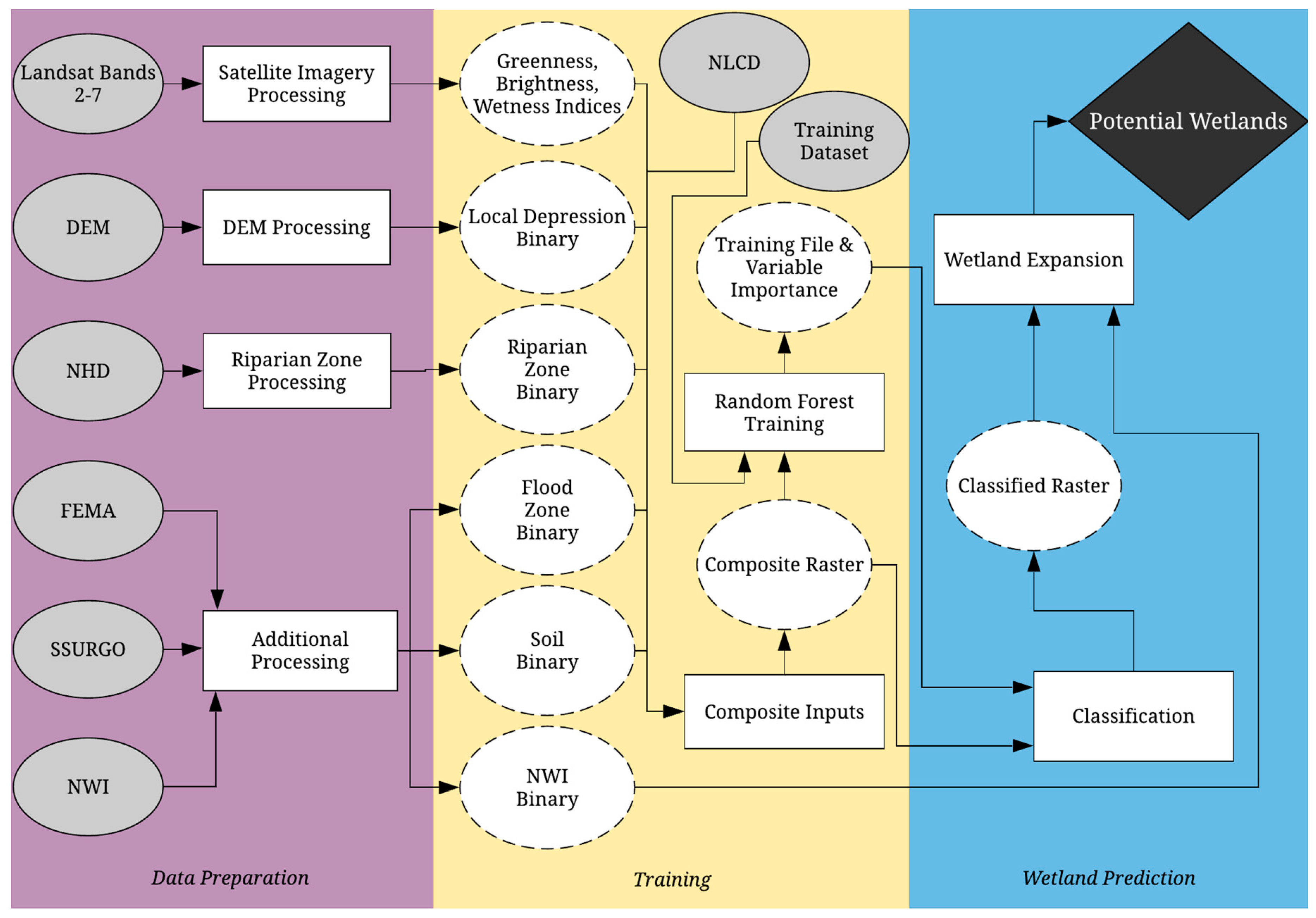
2.3. Screening Methodology Design and Implementation
2.3.1. Data Preparation
2.3.2. Training
2.3.3. Wetland Prediction
2.3.4. Accuracy Assessments
3. Results
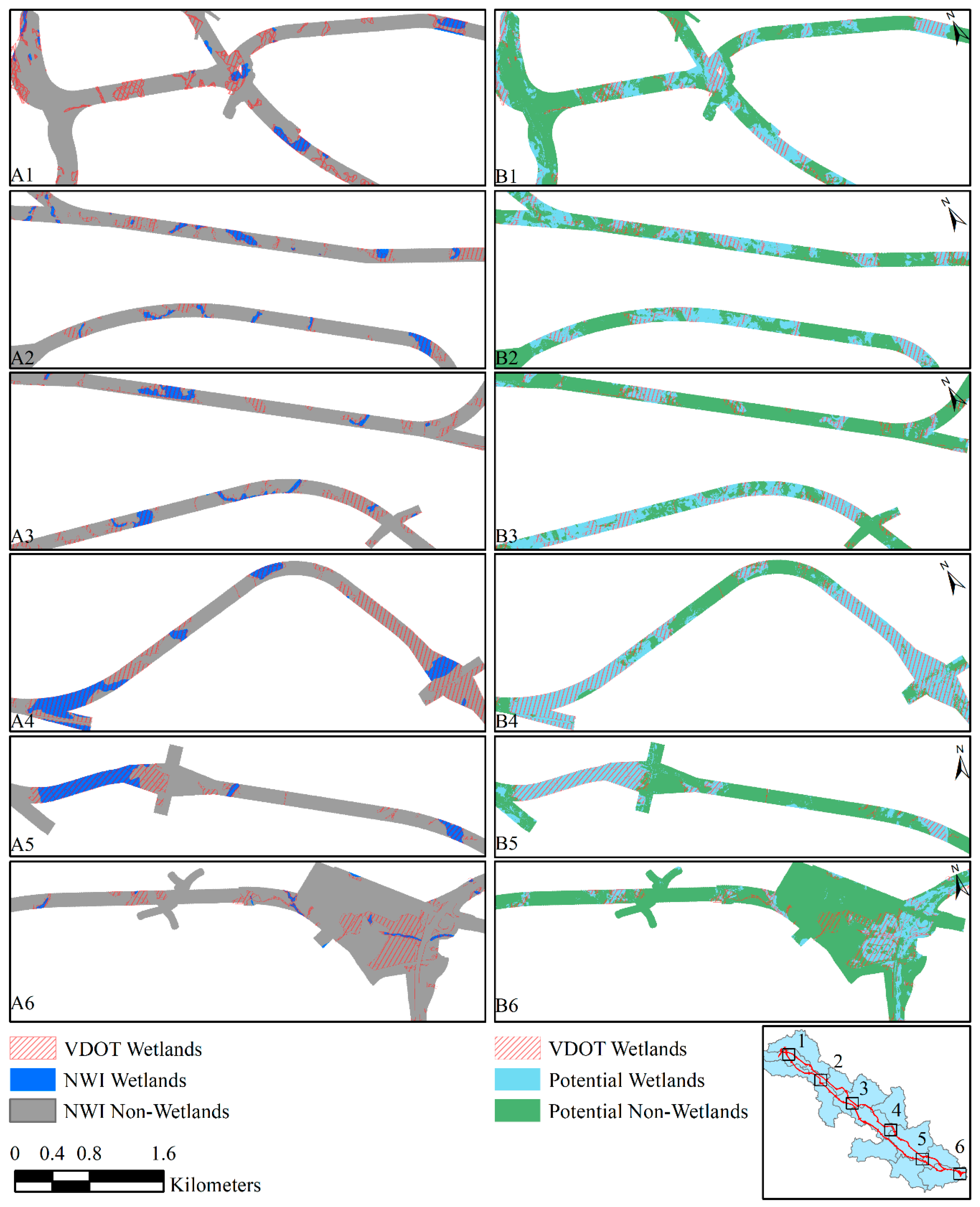
3.1. Screening Method Results Compared to the NWI
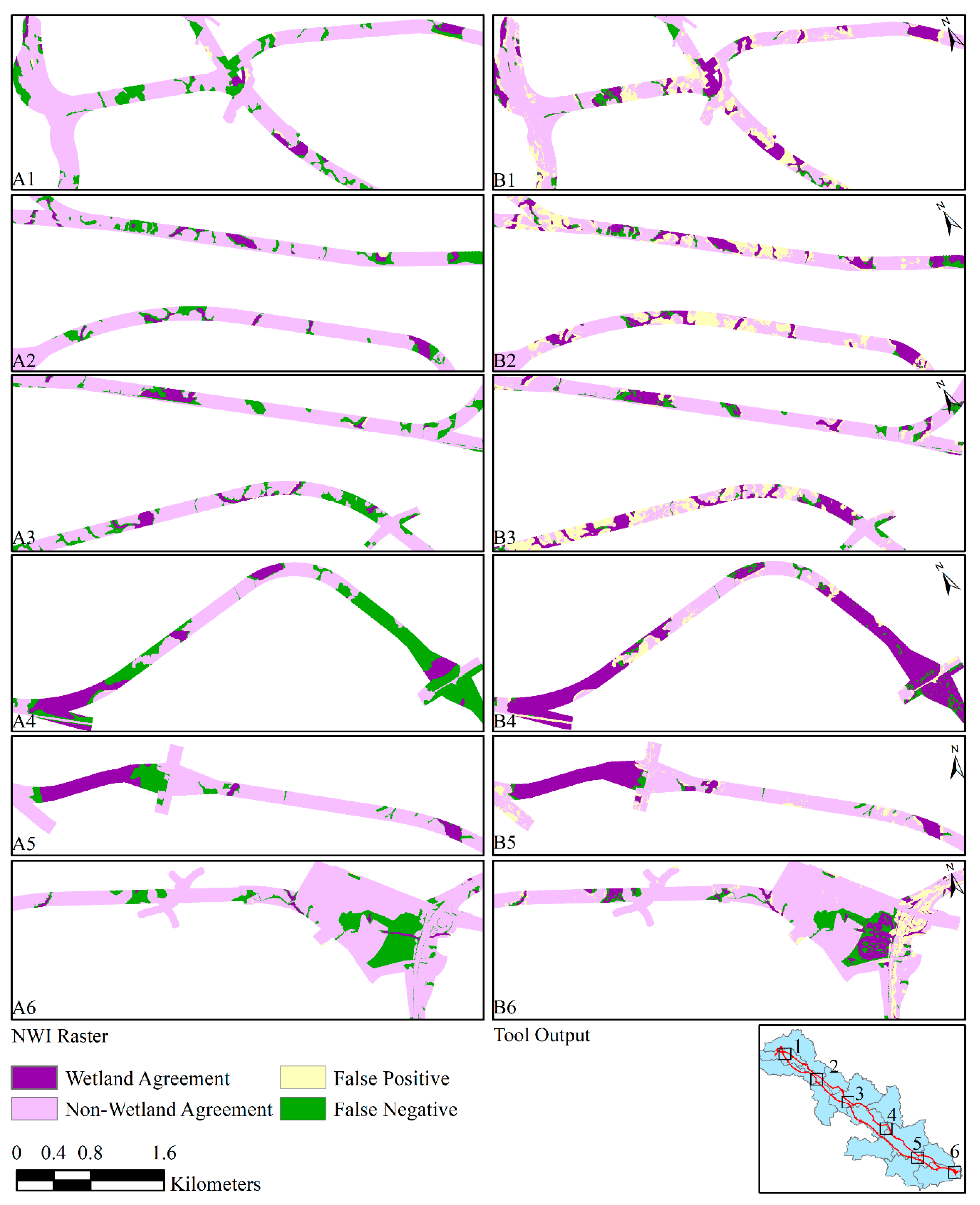
3.2. Confusion Matrix
4. Discussion
4.1. Ecohydrologic Insights into the Method Performance
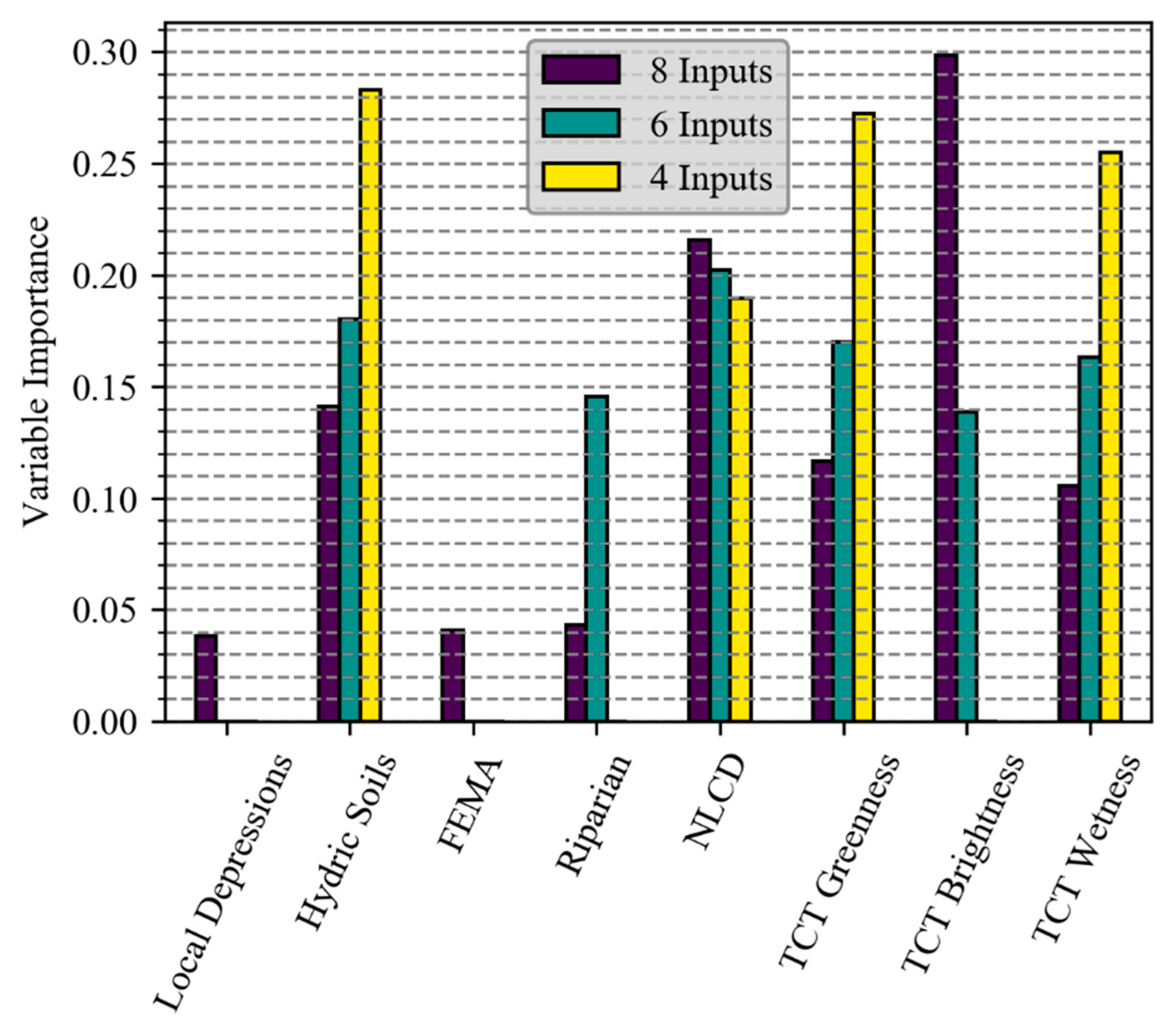
4.2. The Importance of Variable Inputs
4.3. Potential for Additional Data and Tool Improvements
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Klemas, V. Remote Sensing of Wetlands: Case Studies Comparing Practical Techniques. J. Coast. Res. 2011, 27, 418–427. [Google Scholar] [CrossRef]
- Dahl, T.E. Status and Trends of Wetlands in the Conterminous United States 2004 to 2009; US Department of the Interior, US Fish and Wildlife Service, Fisheries and Habitat Conservation: Washington, DC, USA, 2011.
- Votteler, T.H.; Muir, T.A. Wetland Protection Legislation; United States Geological Survey, National Water Summary on Wetland Resources: Reston, VA, USA, 1996; pp. 57–64.
- Page, R.W.; Wilcher, L.S. Memorandum of Agreement Between the Environmental Protection Agency and the Department of the Army Concerning the Determination of Mitigation under the Clean Water Act, Section 404 (b)(1) Guidelines; United States Environmental Protection Agency: Washington, DC, USA, 1990.
- Cowardin, L.; Carter, V.; Golet, F.; LaRoe, E. Classification of Wetlands and Deepwater Habitats of the United States; U.S. Fish and Wildlife Service: Washington, DC, USA, 1979.
- Environmental Laboratory. Corps of Engineers Wetlands Delineation Manual; Technical Report Y-8701; U.S. Army Engineer Waterways Experiment Station: Vicksburg, MS, USA, 1987.
- Tiner, R.W. Use of high-altitude aerial photography for inventorying forested wetlands in the United States. For. Ecol. Manag. 1990, 33, 593–604. [Google Scholar] [CrossRef]
- NWI Program Overview. Available online: https://www.fws.gov/wetlands/nwi/overview.html (accessed on 30 January 2019).
- Cowardin, L.M.; Golet, F.C. U.S. Fish and Wildlife Service 1979 wetland classification: A review. Vegetatio 1995, 118, 139–152. [Google Scholar] [CrossRef]
- Morrissey, L.A.; Sweeney, W.R. Assessment of the National Wetlands Inventory: Implications for wetlands protection. In Proceedings of the Geographic Information Systems and Water Resources IV Awra Spring Specialty Conference, Houston, TX, USA, 8–10 May 2006; pp. 1–6. [Google Scholar]
- Tiner, R.W. NWI maps: What they tell us. Natl. Wetl. Newsl. 1997, 19, 7–12. [Google Scholar]
- Kloiber, S.M.; Macleod, R.D.; Smith, A.J.; Knight, J.F.; Huberty, B.J. A Semi-Automated, Multi-Source Data Fusion Update of a Wetland Inventory for East-Central Minnesota, USA. Wetlands 2015, 35, 335–348. [Google Scholar] [CrossRef]
- Guo, M.; Li, J.; Sheng, C.; Xu, J.; Wu, L. A review of wetland remote sensing. Sensors 2017, 17. [Google Scholar] [CrossRef] [PubMed]
- Rapinel, S.; Bouzillé, J.-B.; Oszwald, J.; Bonis, A. Use of bi-seasonal Landsat-8 imagery for mapping marshland plant community combinations at the regional scale. Wetlands 2015, 35, 1043–1054. [Google Scholar] [CrossRef]
- Woodward, B.D.; Evangelista, P.H.; Young, N.E.; Vorster, A.G.; West, A.M.; Carroll, S.L.; Girma, R.K.; Hatcher, E.Z.; Anderson, R.; Vahsen, M.L.; et al. CO-RIP: A Riparian Vegetation and Corridor Extent Dataset for Colorado River Basin Streams and Rivers. ISPRS Int. J. Geo-Inf. 2018, 7, 397. [Google Scholar] [CrossRef]
- Kaplan, G.; Avdan, U. Monthly Analysis of Wetlands Dynamics Using Remote Sensing Data. ISPRS Int. J. Geo-Inf. 2018, 7, 411. [Google Scholar] [CrossRef]
- Tian, S.; Zhang, X.; Tian, J.; Sun, Q. Random Forest Classification of Wetland Landcovers from Multi-Sensor Data in the Arid Region of Xinjiang, China. Remote Sens. 2016, 8, 954. [Google Scholar] [CrossRef]
- Zhu, C.; Zhang, X.; Huang, Q. Four decades of estuarine wetland changes in the Yellow River Delta based on landsat observations between 1973 and 2013. Water 2018, 10, 933. [Google Scholar] [CrossRef]
- Xiong, D.; Lee, R.; Saulsbury, J.B.; Lanzer, E.L.; Perez, A. Remote Sensing Applications for Environmental Analysis in Transportation Planning: Application to the Washington State I-405 Corridor; WA-RD 593-1; Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2004.
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Millard, K.; Richardson, M. On the importance of training data sample selection in Random Forest image classification: A case study in peatland ecosystem mapping. Remote Sens. 2015, 7, 8489–8515. [Google Scholar] [CrossRef]
- Corcoran, J.M.; Knight, J.F.; Gallant, A.L. Influence of multi-source and multi-temporal remotely sensed and ancillary data on the accuracy of random forest classification of wetlands in northern Minnesota. Remote Sens. 2013, 5, 3212–3238. [Google Scholar] [CrossRef]
- O’Neil, G.L.; Goodall, J.L.; Watson, L.T. Evaluating the potential for site-specific modification of LiDAR DEM derivatives to improve environmental planning-scale wetland identification using Random Forest classification. J. Hydrol. 2018, 559, 192–208. [Google Scholar] [CrossRef]
- Costa, H.; Almeida, D.; Vala, F.; Marcelino, F.; Caetano, M. Land Cover Mapping from Remotely Sensed and Auxiliary Data for Harmonized Official Statistics. ISPRS Int. J. Geo-Inf. 2018, 7, 157. [Google Scholar] [CrossRef]
- Millard, K.; Richardson, M. Wetland mapping with LiDAR derivatives, SAR polarimetric decompositions, and LiDAR-SAR fusion using a random forest classifier. Can. J. Remote Sens. 2013, 39, 290–307. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Miao, X.; Heaton, J.S.; Zheng, S.; Charlet, D.A.; Liu, H. Applying tree-based ensemble algorithms to the classification of ecological zones using multi-temporal multi-source remote-sensing data. Int. J. Remote Sens. 2012, 33, 1823–1849. [Google Scholar] [CrossRef]
- Boonprong, S.; Cao, C.; Chen, W.; Ni, X.; Xu, M.; Acharya, B. The Classification of Noise-Afflicted Remotely Sensed Data Using Three Machine-Learning Techniques: Effect of Different Levels and Types of Noise on Accuracy. ISPRS Int. J. Geo-Inf. 2018, 7, 274. [Google Scholar] [CrossRef]
- Seaber, P.R.; Kapinos, F.P.; Knapp, G.L. Hydrologic Unit Maps: Water Supply Paper 2294; US Geological Survey: Reston, VA, USA, 1987.
- North American Level III CEC Descriptions. Available online: https://www.epa.gov/eco-research/ecoregions-north-america (accessed on 30 Jan 2019).
- USGS. The National Map (TNM) Download. Available online: https://viewer.nationalmap.gov/basic/ (accessed on 30 January 2018).
- Gesch, D.B.; Oimoen, M.; Greenlee, S.; Nelson, C.; Steuck, M.; Tyler, D. The national elevation dataset. Photogramm. Eng. Remote Sens. 2002, 68, 5–32. [Google Scholar]
- Gesch, D.B.; Oimoen, M.J.; Evans, G.A. Accuracy Assessment of the US Geological Survey National Elevation Dataset, and Comparison with Other Large-Area Elevation Datasets: SRTM and ASTER; 2014–1008; US Geological Survey: Reston, VA, USA, 2014. [CrossRef]
- USGS. EarthExplorer—Home. Available online: https://earthexplorer.usgs.gov/ (accessed on 30 January 2018).
- Vanderhoof, M.K.; Distler, H.E.; Mendiola, D.A.T.G.; Lang, M. Integrating Radarsat-2, Lidar, and Worldview-3 imagery to maximize detection of forested inundation extent in the Delmarva Peninsula, USA. Remote Sens. 2017, 9, 105. [Google Scholar] [CrossRef]
- Using the USGS Landsat 8 Product. Available online: https://landsat.usgs.gov/using-usgs-landsat-8-product (accessed on 30 January 2019).
- FEMA. FEMA Flood Map Service Center. Available online: https://msc.fema.gov/portal/home (accessed on 30 October 2016).
- FEMA Flood Zones. Available online: https://www.fema.gov/flood-zones (accessed on 30 January 2019).
- USDA. Web Soil Survey. Available online: https://websoilsurvey.sc.egov.usda.gov (accessed on 30 October 2016).
- Montgomery, G.L. RCA III, Riparian Areas: Reservoirs of Diversity (No. 13); US Department of Agriculture, Natural Resources Conservation Service: Lincoln, NE, USA, 1996.
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 National Land Cover Database for the conterminous United States—Representing a decade of land cover change information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar]
- USFWS. National Wetlands Inventory: Wetlands Mapper. Available online: https://www.fws.gov/wetlands/data/mapper.html (accessed on 30 October 2016).
- Baig, M.H.A.; Zhang, L.; Shuai, T.; Tong, Q. Derivation of a tasselled cap transformation based on Landsat 8 at-satellite reflectance. Remote Sens. Lett. 2014, 5, 423–431. [Google Scholar] [CrossRef]
- Planchon, O.; Darboux, F. A fast, simple and versatile algorithm to fill the depressions of digital elevation models. Catena 2002, 46, 159–176. [Google Scholar] [CrossRef]
- Virginia General Assembly. 9VAC25-830-80. Resource Protection Areas. 1989. Available online: https://law.lis.virginia.gov/admincode/title9/agency25/chapter830/section80/ (accessed on 30 January 2018).
- Hancock, G.; Hamilton, S.E.; Stone, M.; Kaste, J.; Lovette, J. A geospatial methodology to identify locations of concentrated runoff from agricultural fields. JAWRA J. Am. Water Resour. Assoc. 2015, 51, 1613–1625. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s Journal of Software Tools 2000, 25, 120–125. [Google Scholar]
- Train Random Trees Classifier. Available online: http://desktop.arcgis.com/en/arcmap/latest/tools/spatial-analyst-toolbox/train-random-trees-classifier.htm (accessed on 30 January 2019).
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. 2016, 49, 31. [Google Scholar] [CrossRef]
- Lang, M.; McCarty, G.; Oesterling, R.; Yeo, I.Y. Topographic metrics for improved mapping of forested wetlands. Wetlands 2013, 33, 141–155. [Google Scholar] [CrossRef]
- Lang, M.; McCarty, G. Light Detection and Ranging (LiDAR) for Improved Mapping of Wetland Resources and Assessment of Wetland Conservation Projects; USDA, Natural Resources Conseration Service: Washington, DC, USA, 2014.
- Zhu, J.; Pierskalla, W.P. Applying a weighted random forests method to extract karst sinkholes from LiDAR data. J. Hydrol. 2016, 533, 343–352. [Google Scholar] [CrossRef]
- Hogg, A.R.; Todd, K.W. Automated discrimination of upland and wetland using terrain derivatives. Can. J. Remote Sens. 2007, 33, S68–S83. [Google Scholar] [CrossRef]
- Ali, G.; Birkel, C.; Tetzlaff, D.; Soulsby, C.; Mcdonnell, J.J.; Tarolli, P. A comparison of wetness indices for the prediction of observed connected saturated areas under contrasting conditions. Earth Surf. Process. Landf. 2014, 39, 399–413. [Google Scholar] [CrossRef]
- Ågren, A.M.; Lidberg, W.; Strömgren, M.; Ogilvie, J.; Arp, P.A. Evaluating digital terrain indices for soil wetness mapping-a Swedish case study. Hydrol. Earth Syst. Sci. 2014, 18, 3623–3634. [Google Scholar] [CrossRef]
- Murphy, P.N.C.; Ogilvie, J.; Arp, P. Topographic modelling of soil moisture conditions: A comparison and verification of two models. Eur. J. Soil Sci. 2009, 60, 94–109. [Google Scholar] [CrossRef]
- Uuemaa, E.; Hughes, A.O.; Tanner, C.C. Identifying feasible locations for wetland creation or restoration in catchments by suitability modelling using light detection and ranging (LiDAR) Digital Elevation Model (DEM). Water 2018, 10, 464. [Google Scholar] [CrossRef]
- Baker, C.; Lawrence, R.; Montagne, C.; Patten, D. Mapping wetlands and riparian areas using Landsat ETM+ imagery and decision-tree-based models. Wetlands 2006, 26, 465. [Google Scholar] [CrossRef]
- Allen, T.R.; Wang, Y.; Gore, B. Coastal wetland mapping combining multi-date SAR and LiDAR. Geocarto Int. 2013, 28, 616–631. [Google Scholar] [CrossRef]
- Gallant, A.L.; Kaya, S.G.; White, L.; Brisco, B.; Roth, M.F.; Sadinski, W.; Rover, J. Detecting emergence, growth, and senescence of wetland vegetation with polarimetric synthetic aperture radar (SAR) data. Water 2014, 6, 694–722. [Google Scholar] [CrossRef]
- GRASS Development Team. Geographic Resources Analysis Support System (GRASS GIS) Software, Version 7.2. Open Source Geospatial Foundation. 2017. Available online: http://grass.osgeo.org (accessed on 1 June 2019).
- GDAL/OGR Contributors. GDAL/OGR Geospatial Data Abstraction software Library. Open Source Geospatial Foundation. 2019. Available online: https://gdal.org (accessed on 1 June 2019).
- Tarboton, D.G. A New Method for the Determination of Flow Directions and Contributing Areas in Grid Digital Elevation Models. Water Resour. Res. 1997, 33, 309–319. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Area (km2) | Wetlands (km2) | Non-Wetlands (km2) | Wetland to Non-Wetland Ratio | |
|---|---|---|---|---|
| VDOT Delineations | 33.0 | 8.8 | 24.2 | 0.4 |
| Training Data | 3.0 | 0.8 | 2.2 | 0.4 |
| Testing Data | 30.0 | 8.0 | 22.0 | 0.4 |
| Land Classification | Processing Extent | VDOT Delineated Area | ||
|---|---|---|---|---|
| Area (km2) | Percent Area | Area (km2) | Percent Area | |
| Barren Land | 6.52 | 0.5 | 0.15 | 0.5 |
| Developed | 110.25 | 8.1 | 6.85 | 20.8 |
| Forest | 466.59 | 34.2 | 10.61 | 32.2 |
| Grassland | 40.87 | 3.0 | 0.76 | 2.3 |
| Open Water | 10.30 | 0.8 | 0.04 | 0.1 |
| Cropland | 340.00 | 25.0 | 7.68 | 23.3 |
| Shrub | 164.35 | 12.1 | 3.65 | 11.1 |
| Wetlands | 223.62 | 16.4 | 3.24 | 9.8 |
| ∑= | 1362.5 | - | 33.0 | - |
| Landsat 8 OLI | Blue | Green | Red | NIR | SWIR1 | SWIR2 |
|---|---|---|---|---|---|---|
| TCT | Band 2 | Band 3 | Band 4 | Band 5 | Band 6 | Band 7 |
| Brightness | 0.3029 | 0.2786 | 0.4733 | 0.5599 | 0.5080 | 0.1872 |
| Greenness | −0.2941 | −0.2430 | −0.5424 | 0.7276 | 0.0713 | −0.1608 |
| Wetness | 0.1510 | 0.1973 | 0.3283 | 0.3407 | −0.7117 | −0.4559 |
| A | ||||
| Screening Tool Prediction Classes | Testing Data Classes | |||
| Wetland (km2) | Non-Wetland (km2) | ∑ = | ||
| Wetland (km2) | 6.16 | 5.32 | 11.5 | |
| Non-Wetland (km2) | 1.80 | 16.55 | 18.4 | |
| ∑ = | 8.0 | 21.9 | 30 | |
| Overall Accuracy = 76.1% | Kappa Statistic = 0.46 | |||
| False Positive Rate = 24.3% | False Negative Rate = 22.6% | |||
| B | ||||
| NWI Raster Classes | Testing Data Classes | |||
| Wetland (km2) | Non-Wetland (km2) | ∑ = | ||
| Wetland (km2) | 2.45 | 0.28 | 2.7 | |
| Non-Wetland (km2) | 5.53 | 21.62 | 27.1 | |
| ∑ = | 8.0 | 21.9 | 30 | |
| Overall Accuracy = 80.5% | Kappa Statistic = 0.34 | |||
| False Positive Rate = 1.3% | False Negative Rate = 69.3% | |||
| Classification | Overall Accuracy (%) | False Negative Rate (%) | False Positive Rate (%) |
|---|---|---|---|
| 1 | 76.1 | 22.6 | 24.3 |
| 2 | 74.3 | 22.3 | 26.9 |
| 3 | 73.2 | 26.6 | 26.9 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Felton, B.R.; O’Neil, G.L.; Robertson, M.-M.; Fitch, G.M.; Goodall, J.L. Using Random Forest Classification and Nationally Available Geospatial Data to Screen for Wetlands over Large Geographic Regions. Water 2019, 11, 1158. https://doi.org/10.3390/w11061158
Felton BR, O’Neil GL, Robertson M-M, Fitch GM, Goodall JL. Using Random Forest Classification and Nationally Available Geospatial Data to Screen for Wetlands over Large Geographic Regions. Water. 2019; 11(6):1158. https://doi.org/10.3390/w11061158
Chicago/Turabian StyleFelton, Benjamin R., Gina L. O’Neil, Mary-Michael Robertson, G. Michael Fitch, and Jonathan L. Goodall. 2019. "Using Random Forest Classification and Nationally Available Geospatial Data to Screen for Wetlands over Large Geographic Regions" Water 11, no. 6: 1158. https://doi.org/10.3390/w11061158